详解类别不平衡问题
卢总-类别不平衡问题的方法汇总
文章目录
- 从多数类别中删除数据(ENN、Tomeklink、NearMiss)
- ENN
- NearMiss
- 为少数类生成新样本(SMOTE、Borderline-SMOTE、ADASYN)
- 集成方法
- EasyEnsemble算法
- BalanceCascade算法
- 算法层面
- 在线困难样本挖掘 OHEM
- Focal Loss 损失函数的权重调整
- 阈值移动
- 评价指标
从多数类别中删除数据(ENN、Tomeklink、NearMiss)
ENN
NearMiss
非均衡数据处理–如何学习?
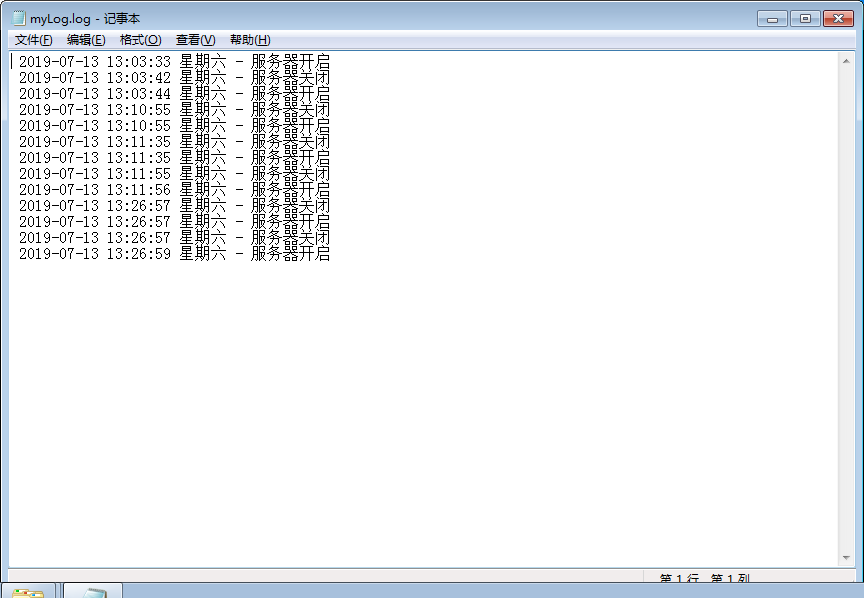
为少数类生成新样本(SMOTE、Borderline-SMOTE、ADASYN)
- Borderline-SMOTE
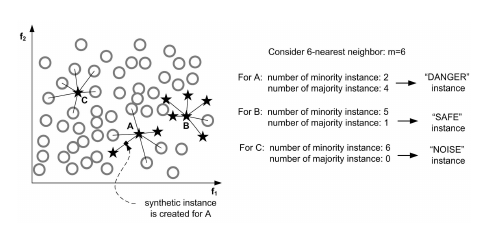
集成方法
随机降采样 + Bagging是万金油。
EasyEnsemble算法
属于bagging
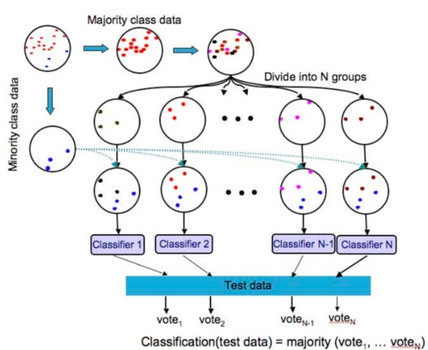

BalanceCascade算法
- 使用之前已经形成的集成分类器为下次寻来呢选择多类样本
假阳性率是auc的横轴

算法层面
目标检测小tricks–样本不均衡处理
Focal Loss — 从直觉到实现
对于不平衡样本导致样本数目较少的类别”欠学习“这一现象,一个很自然的解决办法是增加小样本错分的惩罚代价,并将此代价直接体现在目标函数里。这就是代价敏感的方法,这样就可以通过优化目标函数调整模型在小样本上的注意力。算法层面处理不平衡样本问题的方法也多从代价敏感的角度出发。
在线困难样本挖掘 OHEM
pass
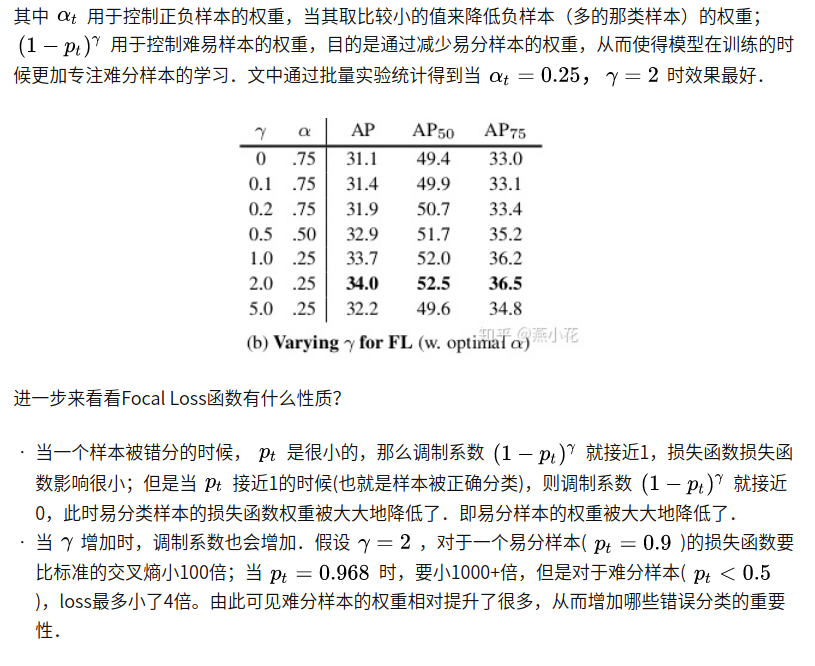
Focal Loss 损失函数的权重调整
Focal Loss — 从直觉到实现
- 类别权重:少数类获得更大的权重
- 难度权重:更专注于比较困难的样本
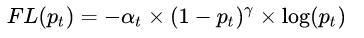
阈值移动
阈值移动主要是用到“再缩放”的思想,以线性模型为例介绍“再缩放”。
我们把大于0.5判为正类,小于0.5判为负类,即若 y 1 − y > 1 \frac{y}{1-y}>1 1−yy>1则预测为正例。

可令 y 1 − y = y 1 − y × m − m + \frac{y}{1-y}=\frac{y}{1-y}\times \frac{m^-}{m^+} 1−yy=1−yy×m+m−然后带入上式。这就是再缩放。
阈值移动方法是使用原始训练集训练好分类器,而在预测时加入再缩放的思想,用来缓解类别不平衡的方法。
评价指标
如果采用ROC曲线来作为评价指标,很容易因为AUC值高,而忽略了少数类样本的实际分类效果其实并不理想的情况。
可以使用聚焦于正例的PR曲线、F1值等;
precision的假设是分类器的阈值是0.5,因此如果使用precision,请注意调整分类阈值。相比之下,precision@n更有意义。

![[linux]cp和mv对文件和链接影响的区别](https://pic002.cnblogs.com/images/2012/172931/2012013020295251.png)